Codename Wojak
Smart trade execution in the cloud, at the edge and everywhere else. Published on 02.01.2022In my previous blog post (Rise of a market participant), I briefly wrote about the infrastructure powering the trade execution, risk management, analytics and observiability of my trading bot.
For a quick recap, I run a bunch of programs which trade on futures and options on the National Stock Exchange, India, on my behalf. These are not high frequency trading bots but rather trade on a positional basis(i.e hold until expiry). The system broadly has the following components
- Data ingestion/transformation
- Trade Execution
- Risk Management
- Trade Analytics
Over the last few months, I made some significant updates to the Trade Execution system, making it more powerful and smart. I wanted to talk about that and the hybrid/multi cloud infrastructure that powers it. This is going to be a 3 part series where the first part is an introduction, the second part is about active operations and the third part is about cost optimization and next goals.
Apart from the Execution System, in part 2 and 3, I will also show an example of running an e-commerce site built on top of Node.js and JQuery on the same infrastructure. With that said, lets dive in.
In the previous blog post, if you looked at the trade execution system, it was basically a converter from one data type to another. It did not have a database nor it had any power to make a decision. It was simple bridge between the risk management system and the broker. I wanted to change this pattern for 2 reasons.
1. The risk management system is very complex and is sometimes an overkill/counter-intutive for simple option statergies and for trades that are near expiry and constant volatility.
2. Due to its complex nature and its dependance on AWS ecosystem, it cannot be easily moved and deployed elsewhere like say a colocated data center in the stock exchange or with a broker.
The risk management system does really good when dealing with hedging short term losses with long term gains and convering volatile in the money positions(not near expiry) with far out of the money options. Basically it should be there and it should be doing its job and should not be disturbed. It also works perfectly well with the AWS Ecosystem both in terms of costs, flexibility and ease of use.
What was needed was a lightweight risk management system that is small, flexible, cheap to operate and is able to take decisions based off certain fixed parameters and if they are breached, forward the trade to the risk management system. By small and flexible, what I mean is this
Small: Should have a small memory footprint and is fault tolerant rather than highly available
Flexible: Should be compatable and run on all cloud platforms, should be able to use various message queues(rabbitmq, SQS, Google Cloud Pub/Sub, HTTP(S) requests) and this should be indepent of the actual trade/decision logic.
Cheap to Operate: The best way to describe this is that I should be left with some cash in the end after paying for trade, losses, brokerage and cloud bills.
With these goals in mind, I ended up with this tech stack
-
Golang: The core trading engine is built in golang. It receives requests from the sidecar container via IPC/TCP sockets using ZeroMQ.
This is the only component that I did not work on. It is written and maintained by a friend of mine. The other components and the architecture was the one I worked on for this project.
- Node.Js: This is the application side car. It receives the input and forwards to the trade engine. This sidecar is designed to handle data from multiple sources and forward it to the trade engine via IPC/TCP sockets using ZeroMQ.
- ZeroMQ: This is a fast, no frills, no non-sense, low memory, multi-protocol and multi-paradigm supported brokerless communication/data interchange library which acts as a bridge between the side car and the trading engine using the IPC paradigm when deployed in the single host and TCP paradigm when deployed in ECS or K8S.
- Couchbase: Having a record of orderbook, tradebook and certain tick values is important to take the decision. I wanted to have a NoSQL database with native cross data center replication and the ability to seperate compute and storage from a logical standpoint. Taking a page from DynamoDB, it would be great to have the data exposed via a REST api as well. Considering all of these scenarios, I ended up going with couchbase. Also, its the only NoSQL database that my friend is comfortable with. The data is eventually consistent but the application is designed to deal with this scenario.
The System Architecture
The initial version is deployed on AWS and Google Cloud Platform. The architecture looks like this.
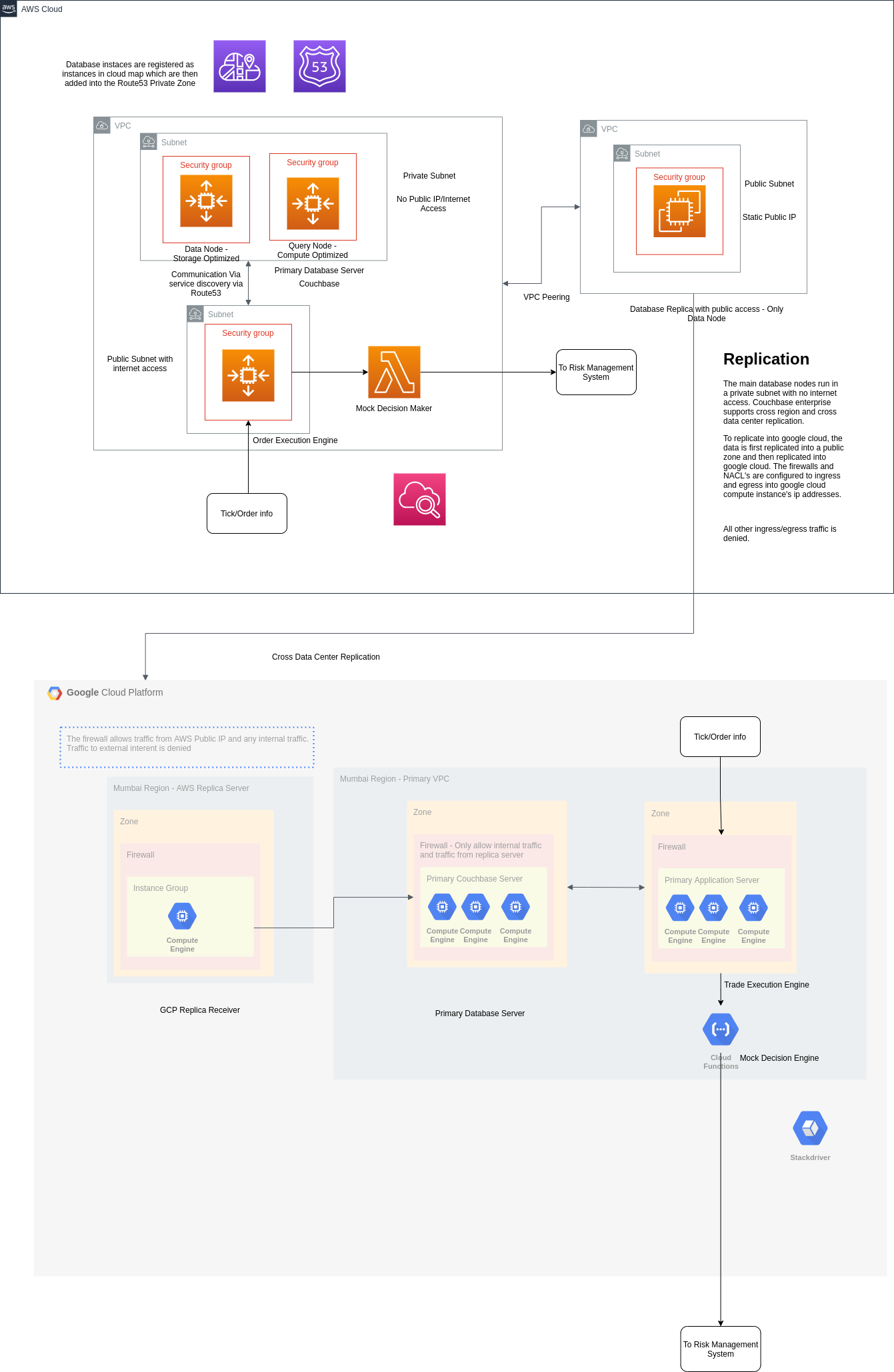
I dont want to go over the specifics and the metrics of the system in this blog post as it would end up being a very long one. I will go on detail in part-2. But I will touch over some basic points to set the context for the future posts.
For the initial version, the database and the application server are running in VMs as docker containers within a container optimized os. However in production, I plan to deploy them in K8S or another container orchestrator like ECS or OpenShift. Another point to node is that while the system in theory does active trading, in practice the orders are not sent to the exchange. Rather they are evaluated by a lambda function and are randomly marked as success or failed(basically running in a sandbox).
Database
The database(Couchbase Enterprise) is seperated into compute and storage nodes. The storage nodes act as a source of truth for data and are deployed in reserved or on-demand instances. The compute/query nodes act as a gateway to query from the data nodes. These compute nodes are deployed as spot instances.
The advantage of having a system like this is that we could scale the compute and analytics nodes to any scale on spot instances making it cost effective. If the instances are terminated the system is still available to query via the data nodes until new compute nodes are back online.
The other powerful feature of Couchbase is its replication protocol. Taken from Apache CouchDB, it offers seamless replication across regions and data centers making it an effective cross cloud NoSQL database.
The nodes are registered as in a service discovery and are accessed via the internal dns.
The Compute Environment
I initially thought of running them on reserved instances but over time, as the application is inherently fault tolerant and the fact that you could pair multiple compute environments with ecs/eks and GKE made me go with spot instances.
In due course I envision the database to be running like this
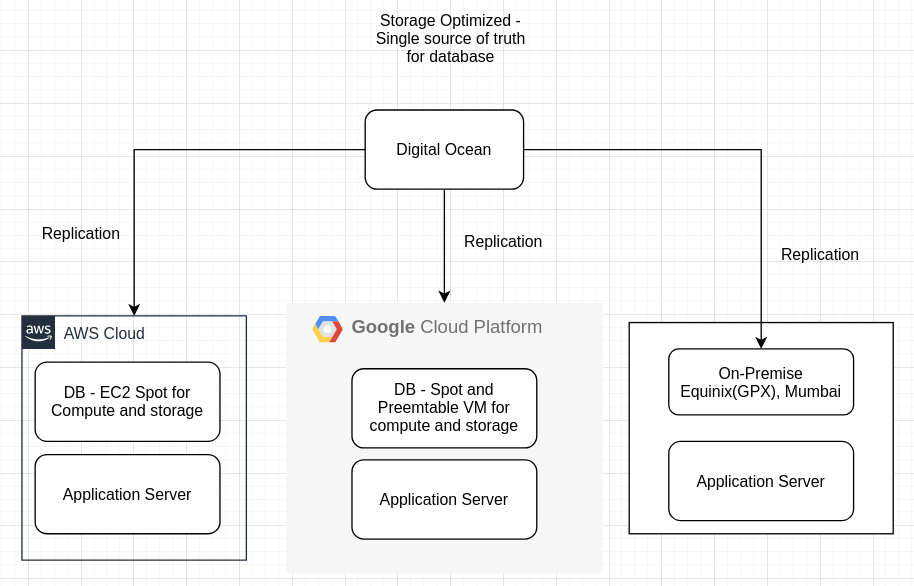
The application servers will be deployed into their independent cloud platforms and the database will be replicated as well and all of this would be running in spot instances. While the system architecture shows VMs in an autoscaling group, this would be replaced by either kubernetes any other container orchestrator + a service discovery.
Why ZeroMQ?
The usage of ZeroMQ was something like a peace deal b/w me and my friend who was building the trade engine. I was incharge of the communication layer and he was incharge of the decision layer. So, I would write high level apis for various message brokers and publish them as sdks for him to consume(in a monorepo). However over time, this became cumbersome and it was also rather difficult to maintain compliance over the integrity and accountablity of the algorithm due to the number of people who are able to access and edit the codebase.
Inspired by Istio's architecture, we decided to go with a structure where the inter-service communication would be decoupled with that of the external communication and that the application server will have a sidecar talking to it via IPC or TCP. All that the application server needs to know is receive a request via ZMQ via the sidecar and send an acknowledgement. The sidecar will take care of requeing/acknowleding with the respective broker.
While this started as a peace deal, it ended up being the single best decision we made when it comes to the application architecture. This allowed me to pair broker, cloud and environment in any cloud that I wanted. The flow of request looks like this
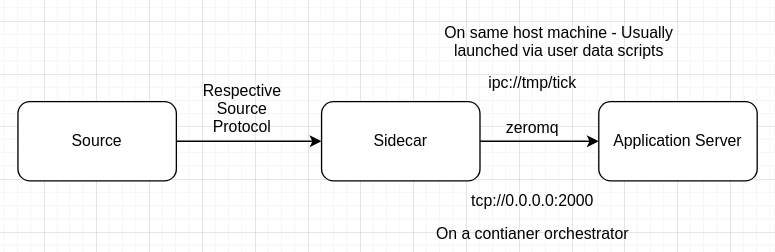
For now, the sources are
- AWS SQS
- AWS SNS
- AWS Step Functions
- Google Cloud Pub/Sub
- Apache Kafka
- AWS Kinesis
- RabbitMQ
- HTTP(S)
The code for the sources are published as independent docker containers and tagged with the same name in the registry. The deployment files(k8s manifest, terraform templates) are edited to include the respective source and credentials(if any) are passed as environment variables to the container orchestrator.
So what's next?
In the sandbox with the live trade data, I was able to achieve 50,000 orders per minute execution capacity with 20 VMs(15 compute and 5 database). However the system a considerable amount of friction when dealing with live tick data. I plan to ease out these issues over the next few weeks and deploy the system atleast 1 week before the January month's expiry day(27.01.2022) and see the trading efficiency over that week.
But more than this, I want to actually try this idea with a full functioning e-commerce site. The idea that we could run all our production workloads on spot instances without worrying about data corruption seems very far fetched but I want to give it a shot anyways.
Stay tuned for the next blog post, Spot The Difference, with more in-detailed walkthrough of the system, some metrics and my experience with working on spot instances for production workloads.
Until then, adios.
PS: If you have any ideas or suggestions that you want me to try, feel free to hit me up either via linkedin or the form in the home page or drop me an email at hello@backend.engineer. I will be more than happy to try them out.